Resource - Sherlock
In the era of Big Data, data collection underpins biological research more so than ever before. In many cases this can be as time-consuming as the analysis itself, requiring downloading multiple different public databases, with different data structures, and in general, spending days before answering any biological questions. To solve this problem, we created an open-source, cloud-based big data platform, called Sherlock (github). Sherlock provides a gap-filling way for computational biologists to store, convert, query, share and generate biology data, while ultimately streamlining bioinformatics data management. The Sherlock platform provides a simple interface to leverage big data technologies, such as Docker, PrestoDB or HIVE Metastore. Sherlock is designed to analyze, process, query and extract the information from extremely complex and large data sets. Furthermore, Sherlock is capable of handling different structured data (interaction, localization, or genomic sequence) from several sources and converting them to a common optimized storage format. This format facilitates Sherlock’s ability to quickly and easily execute distributed analytical queries on extremely large data files. The Sherlock platform is freely available on github, and contains specific loader scripts for structured data sources of genomics, interaction and expression databases. With these loader scripts, users are able to easily and quickly create and work with the specific file formats. For further details, please check our publication about Sherlock: (Bohár B. et al, 2021).
For full-sized version, please click on the image.
Deployment
For Sherlock, we developed a dockerized version of Presto that also incorporates the Hive metastore. This addition of both the query engine and metastore makes Sherlock cloud-agnostic, so it can be installed at any cloud provider, providing it is a Linux machine with Docker installed. The advantage of running Presto in a dockerized environment is that it is not necessary to install and configure the whole Presto Query Engine manually. Furthermore, it can even be fired up on a local machine, multiple machines or any cloud service as well. On the deployment guide section of the GitHub page of Sherlock (github), we show how to make a set of Linux virtual machines with Docker installed, then start a distributed Presto cluster by using the Sherlock platform.
Our Data Lake solution
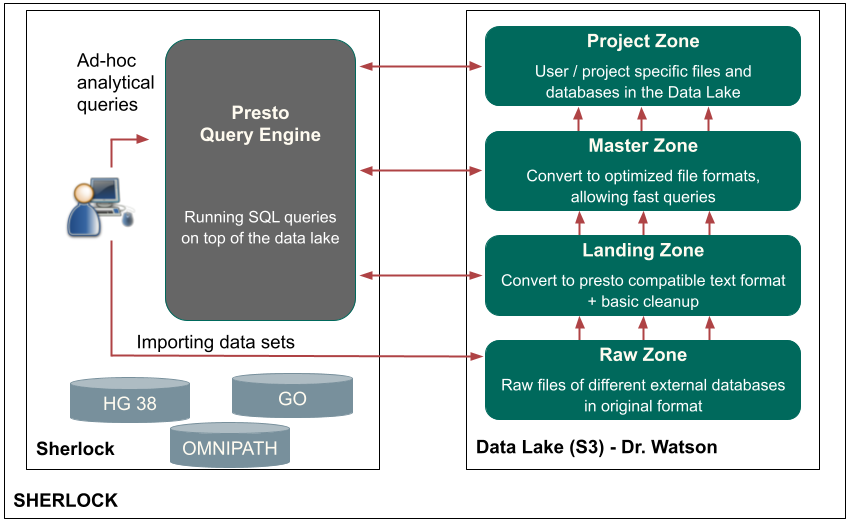
Having somewhere to store the data is only one half of having an operational Data Lake. One can not stress enough how important it is to organize the data in a well defined ‘folder’ structure. Many Data Lake deployments become unusable after a few years due to poor maintenance, resulting in a large amount of data ‘lost’ in the thousands of folders, or inconsistent file formats and no ownership over the data. Our solution is to separate all of the data in the Data Lake into four different main folders, representing different stages of the data and different access patterns in the Data Lake. Inside each of these main folders we can create subfolders, and it is a good practice to incorporate the name of the dataset, the data owner name, the creation date (or other version info), and the file formats somehow into their paths.
We separated our Data Lake into four different main zones, which are built on top of each other.
The first zone is the raw zone. Into the raw zone, we archived all the database files in their original formats. For example: if we downloaded the human genome, then we put the fasta files here, under a separate subfolder. Usually, these files cannot be opened with Presto, as the file format is incompatible in most of the cases.
The next zone is the landing zone. We needed to develop specific scripts, called loader scripts, converting and extracting the raw datasets into this zone. We converted the data to a text file in JSON Lines format, which can be opened by Presto. This is a specific JSON format, where each line of the text file represents a single JSON record. Each JSON file for a given dataset is placed into a separate sub-folder in the landing zone. It is then registered by Presto which sees the dataset now as a table. Then, Presto will be able to load the data, and perform other operations, for example it can execute simple data transformations on the data.
Using Presto, we converted the data from the landing zone into an optimized (ordered, indexed, binary) format to the third zone, which is the master zone. The main idea is that we use the tables in the master zone later for the exact analytical queries. Here the data is in a more detailed and exact format, called Optimized Row Columnar (ORC), which is a free and open-source column-oriented data storage format (https://orc.apache.org/docs/). With ORC, Sherlock can perform SQL queries much faster than using the JSON text file format from the zone below.
The last zone is the Project zone. This is where we are saving the tables which are needed only for specific projects. We can even create multiple project zones, one for each group, project or user. It is important to have a rule to indicate the owner of the tables, as mentioned before this dramatically increases the effectiveness of Sherlock and ease of maintenance.